QA Arena tests QA-generation strategies before you scale them.
You have a QA-generation use case. Many strategies are possible: different evals, models, provider tools, source-enrichment methods, research ideas, and budgets. QA Arena turns those choices into controlled experiments and shows what is worth scaling.
A team does not start with a leaderboard. It starts with questions.
QA Arena turns those questions into small controlled experiments. The output is a decision:
Which evals actually measure the failure modes that matter?
Which generator or provider performs better for this use case?
Does source enrichment improve the result?
What changes when generation runs locally, in the cloud, or through an agentic runtime?
Does more generation volume improve quality, or only produce more candidates?
Can an idea from a paper become a better QA-generation or evaluation method?
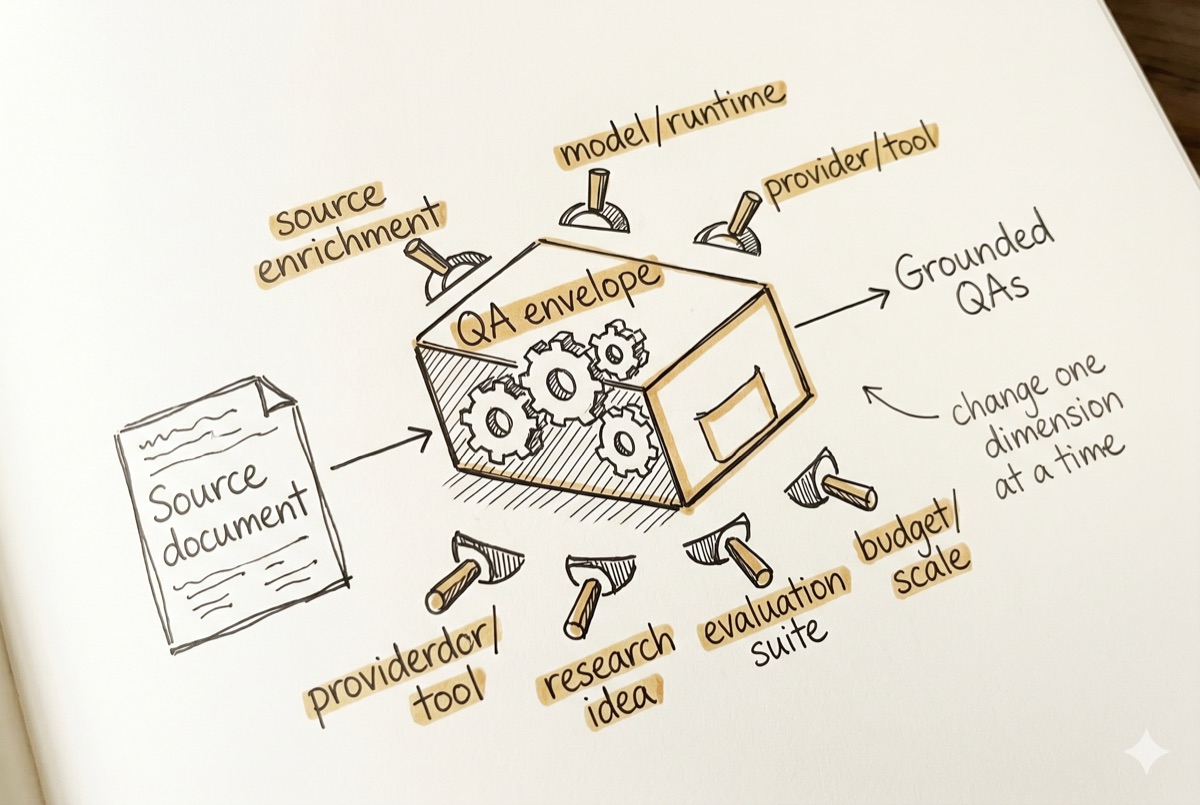
Fig. 1 — Grounded Document QA, strategy choices under test
Grounded Document QA
Generate trustworthy QAs from source documents.
QA Arena then tests competing strategy choices around that use case:
QA Arena does not publish global winners.
Distilabel is better than DeepEval.
This model is the best.
This enrichment method always wins.
For this use case, under these conditions, this strategy produced stronger evidence.
No global winners. Scoped evidence only.
A result is valid inside its use case, source, strategy, evaluator, model, budget, and evidence stage.