Grounded Document QA.
One use case, many possible QA strategies. We fix the goal — generate trustworthy QAs from source documents — and explore the dimensions that may change the result.
Audited observed · 2026-06-13 · Evidence stage: Pilot
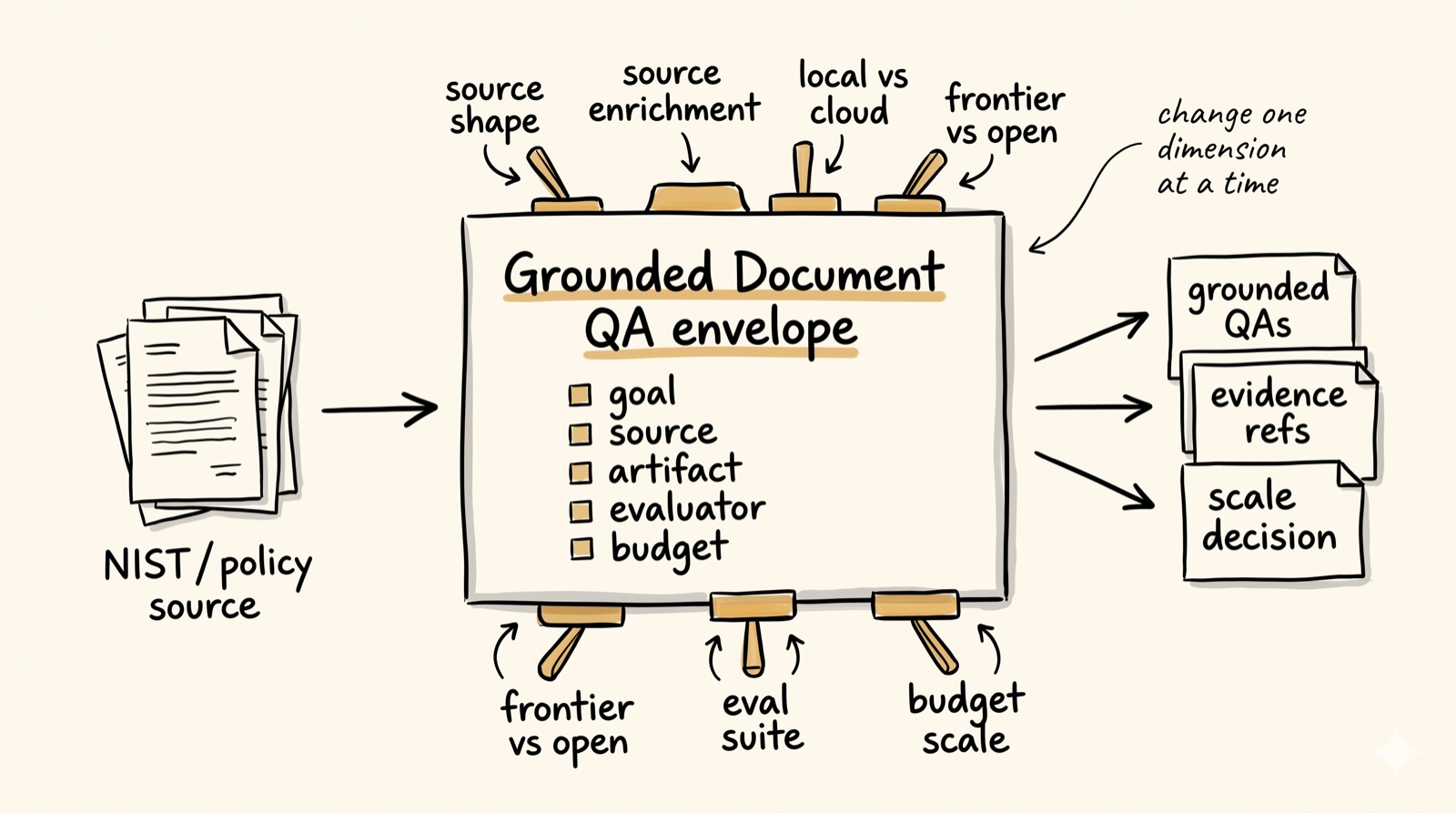
Fig. 1 — the worked envelope
A team has source documents and wants grounded question-answer pairs. The QAs must be answerable from the source, faithful to the source, and useful for evaluation, training, compliance, or RAG testing.
The QA envelope is the controlled experimental frame around the use case. It fixes use case, source, output format, evaluator, and budget; then varies one dimension at a time.
Each dimension changes one thing about the envelope, while every other choice stays fixed.
Does the same grounded-QA pipeline hold across policy, technical, and code source documents?
Does pre-processing the source (raw vs summary vs clause map) change grounded-QA quality?
Does the same pipeline work on a local Ollama model and a cloud API model?
Does a frontier model meaningfully outperform an open-weight model under the same envelope?
Does the routed metric suite discriminate quality differently from a generic LLM-judge suite?
Does candidate volume (50 / 100 / 200) change which strategies win, or just how many you keep?
The current evidence suggests QA-generation quality depends on more than the generator. Source preparation, evaluator choice, model/runtime, and candidate budget all affect what can be trusted. The strongest current value of this envelope is not declaring a universal winner, but showing which dimensions are worth testing before scale-up.
The current evidence is still pilot-grade. It does not yet prove a universal best tool, best model, or best enrichment strategy. More source families, repeated runs, and clearer arm-level comparisons are needed before making robust claims.
- A second source family (codebase, scientific paper) to retest source enrichment and source shape outside the policy domain.
- A second model per arm in the frontier-vs-open-source dimension.
- A noisier candidate set for the evaluation-suite null result.
- A larger budget arm (500 candidates) to test the volume-without-quality-collapse finding at scale.