How a claim earns the word evidence.
The envelope, the dimensions we vary, the Strategy Execution Test, how results are interpreted, and the maturity scale that bounds every claim.
What is a QA envelope?
The controlled experimental frame around a use case. It fixes the use case, the source family, the artifact contract, and the candidate floor — then varies one dimension at a time. Claims are valid only inside the envelope tested.
“Under these conditions, this strategy worked better than the alternatives we tested.”
Why global leaderboards mislead
A strategy that wins for compliance QA on long policy docs may lose for medical QA on short clinical notes. A strategy that wins under one evaluator may tie under another. Global “best strategy” claims hide the dimensions that actually changed the result.
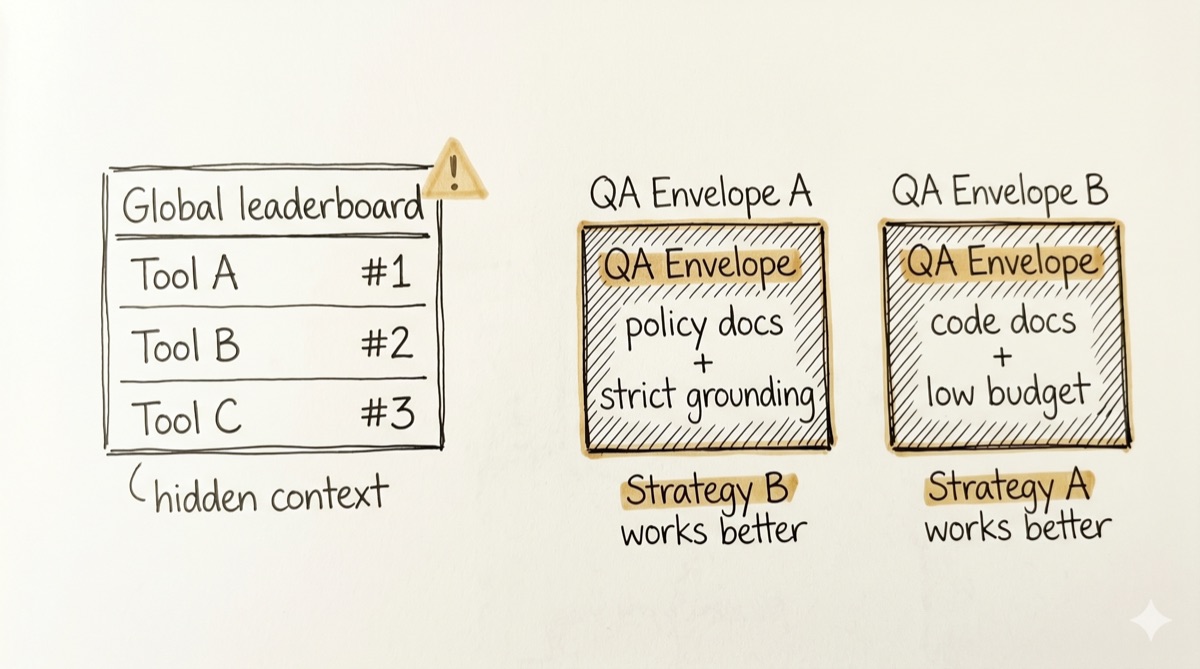
Fig. 1 — same tools, different envelopes, opposite winners
Dimensions that can change a result
Each run carries a pre-registered statement of what it must demonstrate and what would count as failure. After the run, an audit closes it as one of four states.
Produced the artifacts the contract required.
Some arms met the floor; others fell short.
Did not produce the required artifacts.
Hit a boundary — recorded as evidence about it.
Five levels. Maturity is not output quality — a pilot can produce high-quality outputs and still be weak evidence because the sample is small. Everything on this site is currently Pilot.
“In this envelope, strategy Y performed better on the tested slice.”
“This pilot suggests Y is worth scaling, but the sample is small.”
“Changing the evaluator changed which arm looked best.”
“Tool X is best.” · “Strategy Y is best.”
Any global ranking not scoped to an envelope.
Any statistical-significance claim — no p-values here.