I thought I had built the right architecture.
I was working on Inquirer: an ask-mode system for cases where the answer is not the hard part — the hard part is asking the better next question.
The goal was to support requirements discovery, clarification chains, audits, interviews, and other elicitation workflows. To implement it, I was applying recent research papers about elicitation and question-asking strategies. I had designed a careful architecture: planning, routing, structured reasoning, and paper-inspired decision paths.
It was not a toy. It was explicit, modular, testable, and controlled — exactly the kind of system architecture I would normally trust.
And it worked.
But "it works" is not the same as "it is the right abstraction."
So I tested it against a different baseline: a general-purpose agent coder, given the right context, prompt, and harness.
Most of the time, the custom architecture held its ground. Then one case broke my confidence. The agent coder produced the same result with fewer steps. It did not follow the carefully designed path. It reasoned around it.
The agent did not merely execute faster. It recognized that, for that specific case, some of the architecture's complexity was unnecessary. It simplified the strategy, skipped parts of the planned workflow, and still reached the goal.
That was the lesson: even the most advanced algorithmic workflow can be beaten by an agent coder that spots an optimization.
The conclusion is not that static software is dead. Static code remains the right answer for many systems. If the workflow is stable, deterministic, regulated, cheap to execute, and well understood, static software is probably preferable.
The conclusion is narrower: for adaptive workflows, where the correct path depends on runtime context, too much intelligence frozen at build time becomes brittle.
The limit of build-time intelligence
The current development pattern treats AI agents mostly as build-time assistants. We ask them to write code, we review the code, and then we deploy a static artifact. Useful, but incomplete.
Some systems do not have a complete specification upfront. Discovering the specification is part of the work. The system may need to decide what kind of task it is handling, whether the input is reliable enough to use, which tools are appropriate, whether a failed step is a bug or a blocker, whether more evidence is needed, or whether it should stop and ask for approval.
Trying to hardcode every possible path creates a maze of brittle orchestration logic. You end up building routes for yesterday's cases.
Traditional development
Developer writes code, deploys a static artifact
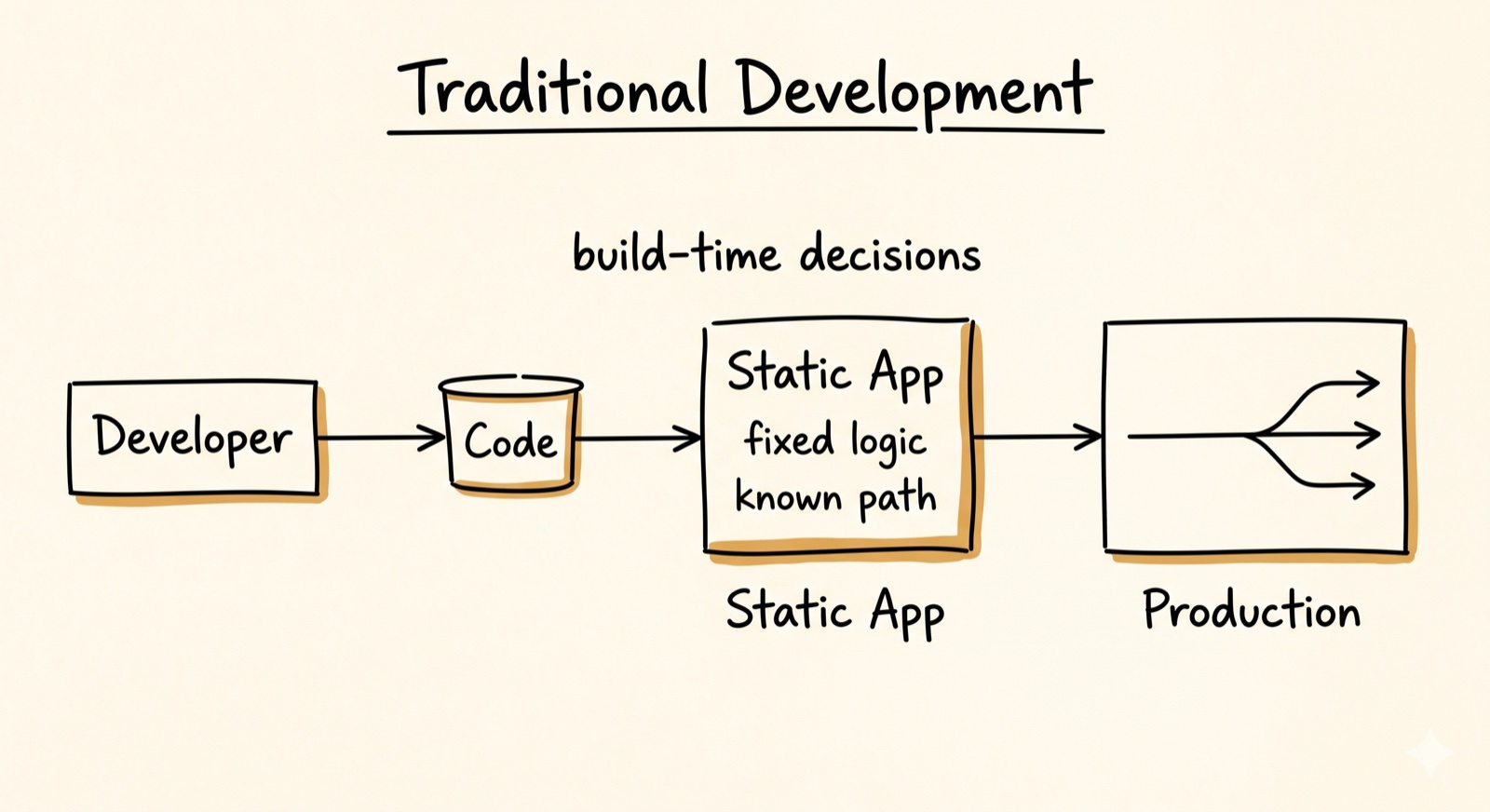
All intelligence is frozen at build time. The deployed system executes exactly what was written.
AI-assisted development
Agent coder helps write code, but the output is still static
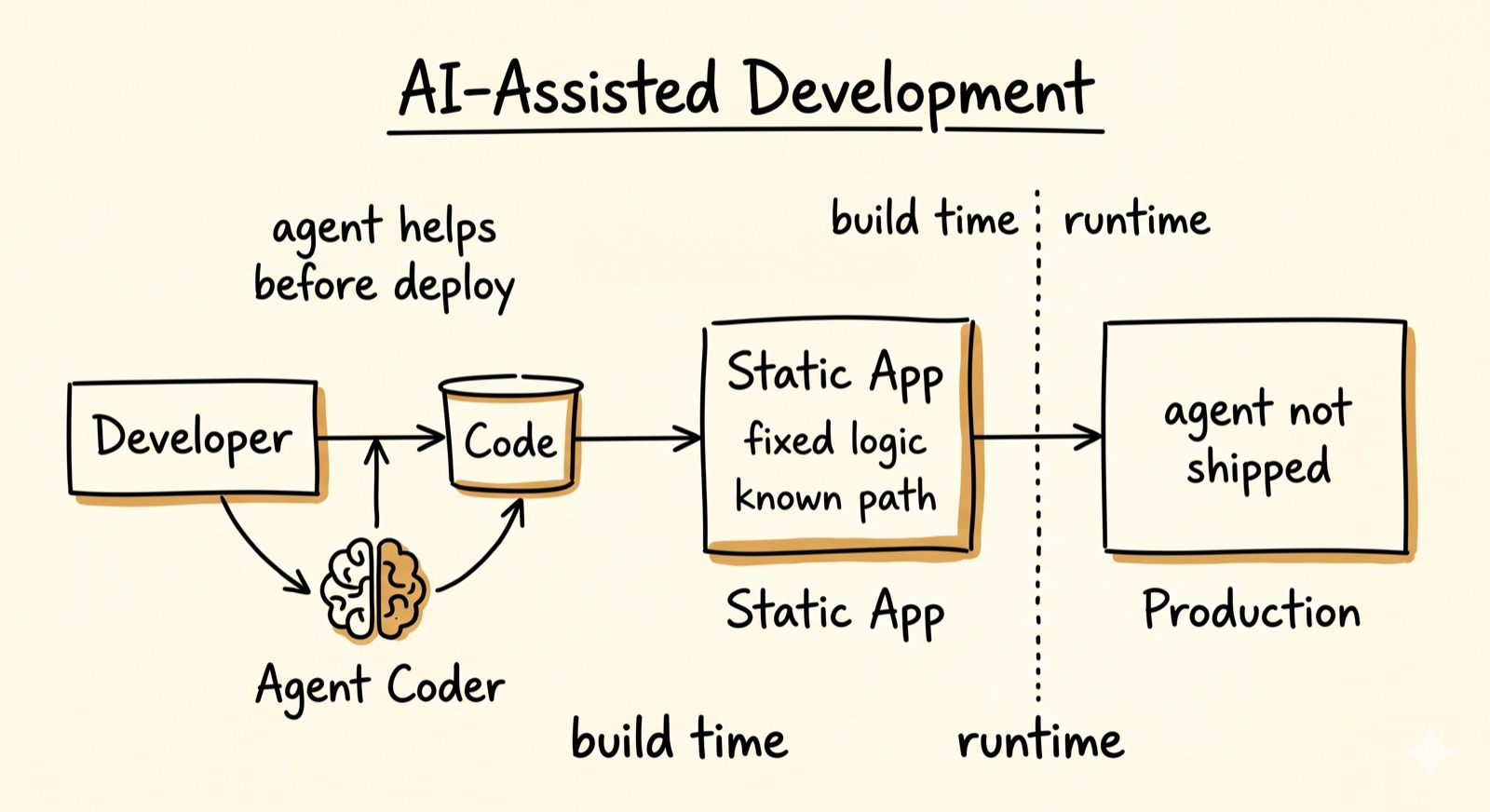
Build-time intelligence improves. The deployed artifact does not change. The agent stays behind.
Instead of using an agent coder only to build the application, what if the agent coder became part of the application boundary?
Not as an unrestricted chatbot. Not as a magical autonomous worker. Not as a replacement for software engineering.
As Agent Code.
That is the Living Code pattern: the application ships with software plus constrained Agent Code that can reason at runtime, use tools, write software when allowed, record evidence, and stop when review is required.
Living Code
The application ships with software plus Agent Code inside a controlled boundary
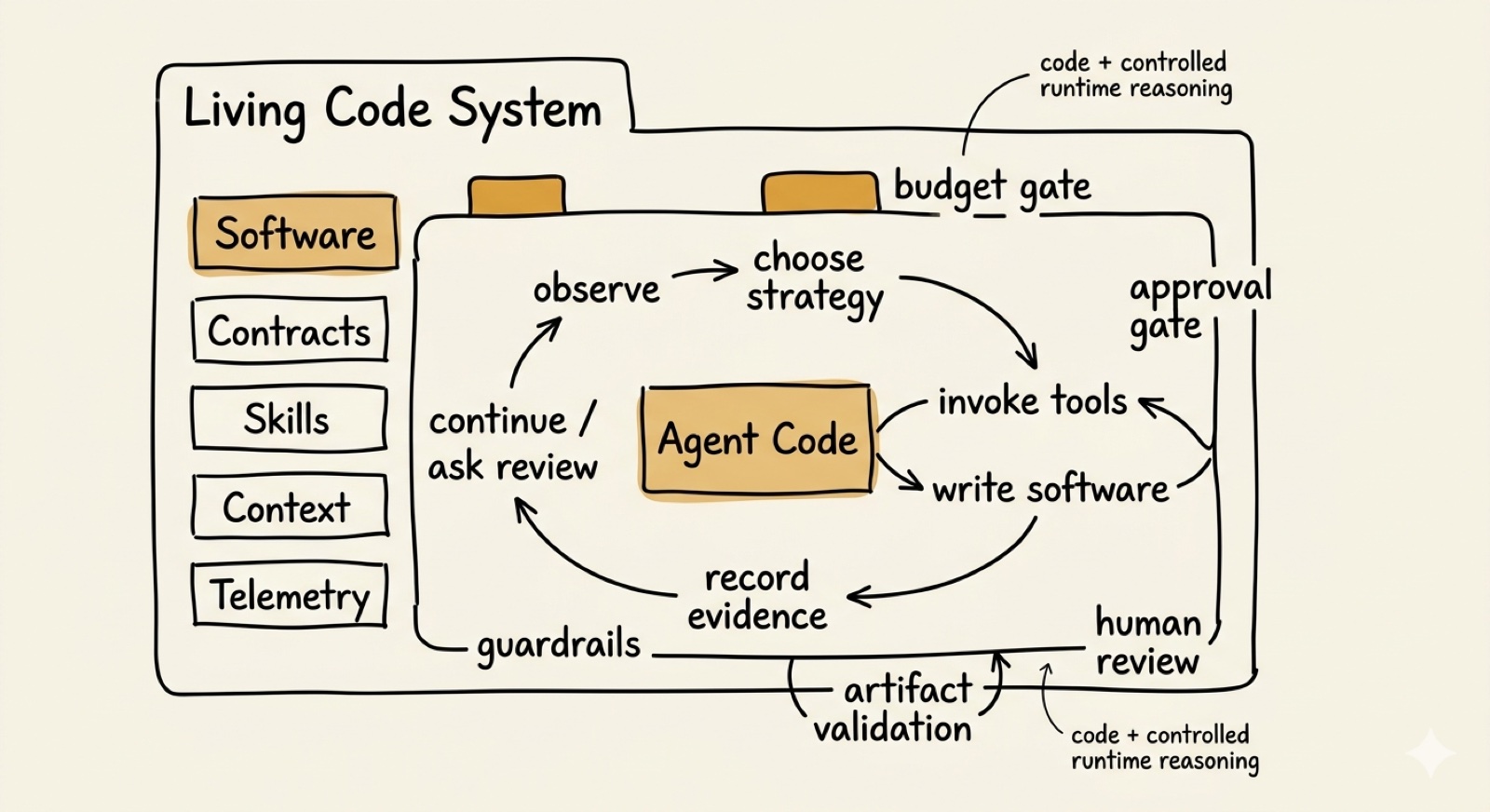
Runtime reasoning. The application still owns the hard contracts, but Agent Code can navigate the adaptive path: inspect context, choose a strategy, invoke tools, write software when allowed, record evidence, and stop for review.
The application is still code
The more reasoning moves to runtime, the more important the hard software boundary becomes. Code should still own what code is good at: schemas, validation, normalization, artifact contracts, permissions, telemetry, reproducibility, storage, and deterministic execution paths when those paths are known.
Agent Code should not replace those contracts. It should operate inside them.
The application provides the environment. Agent Code reads the context, follows the skills, chooses among allowed strategies, invokes tools, records what happened, and stops when the evidence is insufficient or the policy requires review.
The deployed system is no longer only static code. It is software plus Agent Code, skills, context, memory, telemetry, provenance, budget rules, approval gates, and review discipline. For adaptive workflows, this can be simpler than pretending every decision can be compiled into a static pipeline ahead of time.
Agent Code may generate or modify software when needed, but the principle is not to turn every uncertainty into permanent code. Keep the fixed code perimeter low: hard-code contracts, validation, telemetry, permissions, and stable paths; leave uncertain strategy choices to runtime reasoning until they prove reusable.
The knowledge layer is not a document dump
For Living Code, the knowledge layer should not merely store information. It should translate information into possible action.
A research paper should become claims, assumptions, proposed strategies, metrics, and reproduction plans.
An open-source tool should become supported modes, input contracts, output contracts, known failure modes, and candidate experiment arms.
A prior run should become observations, scoped beliefs, evidence strength, unresolved questions, and possible next experiments.
Without this layer, runtime reasoning becomes improvisation.
With it, Agent Code can choose strategies from a living map of what has been proposed, what has been tried, what failed, what worked, and under which conditions.
Runtime reasoning creates a governance problem
Moving intelligence to runtime solves one kind of brittleness, but it creates another problem: control.
If the path is not hardcoded, how do you make sure Agent Code does not invent a new goal? How do you keep the work reproducible? How do you prevent runaway cost? How do you preserve failures instead of letting the agent silently repair or hide them? How do you know which tool version, model, prompt, source slice, or evaluator produced a result?
This is where OpenClaw becomes a natural fit.
OpenClaw is not interesting here as another generic agent framework. It is interesting because it already points toward a control plane for agent coders: skills, contracts, context, tools, telemetry, budgets, human review, and handoff.
Living Code needs exactly that kind of boundary.
Agent Code needs more than access to tools. It needs inspectable memory, executable skills, budget controls, approval gates, artifact validation, telemetry, provenance, and closeout discipline. It needs a way to say not only "this succeeded," but also "this partially worked," "this was blocked," or "this is unverifiable."
The point is not to make the system look autonomous. The point is to make runtime intelligence auditable.
OpenClaw Gateway
A shared control plane for multiple Living Code Systems
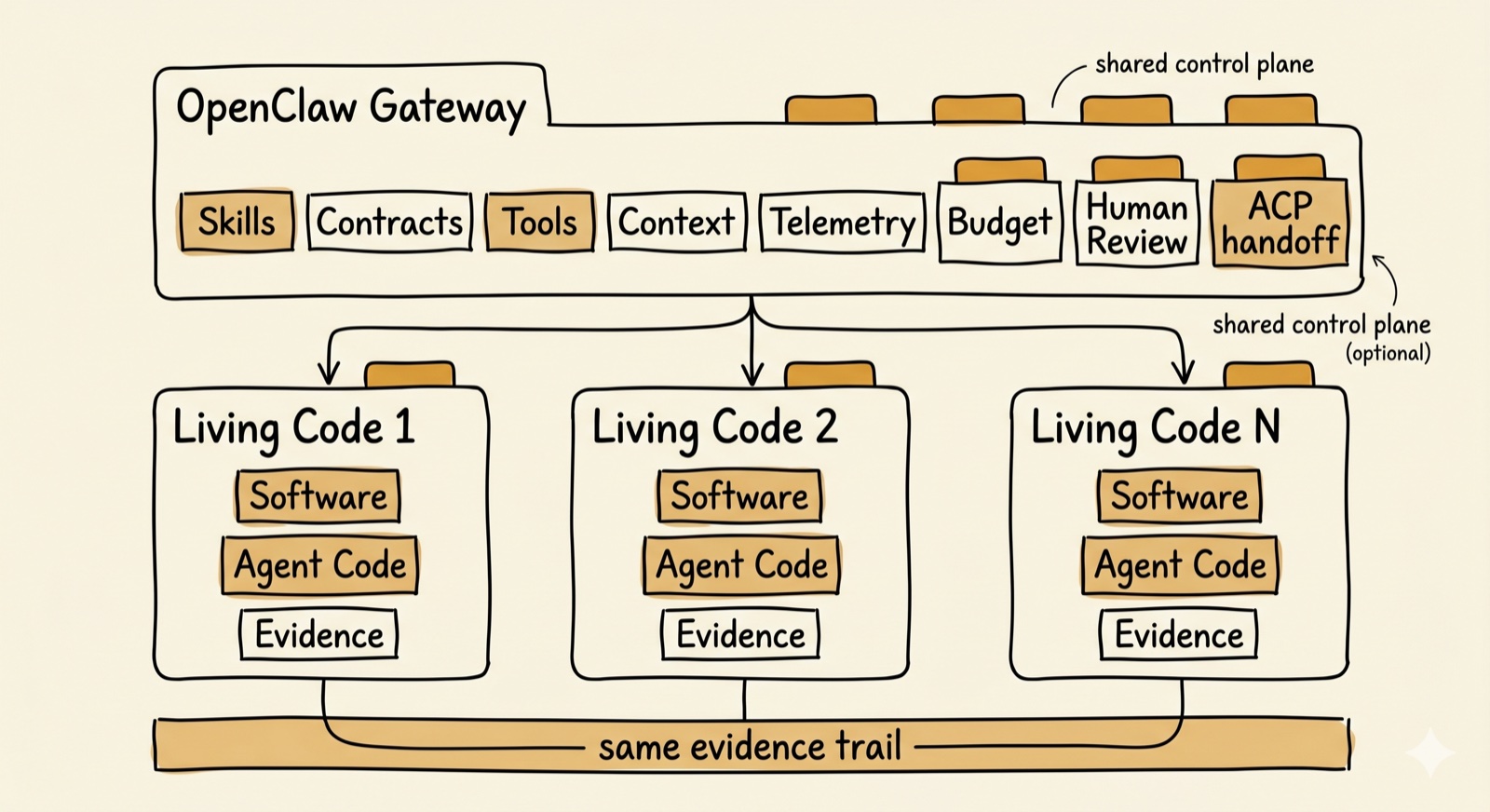
The gateway is not one agent. It is shared infrastructure where multiple Living Code Systems run under common skills, contracts, tools, telemetry, budgets, and human review. ACP handles handoff between them; every system writes to the same evidence trail.
Failure should become evidence
In traditional automation, a failed run is something to retry, patch, or hide. In a Living Code System, failure is information.
An invalid output is information. An empty response is information. A tool that cannot handle a certain input shape is information. An evaluator that produces unstable scores is information. A workflow that cannot proceed because the source is not ready is information.
Recording those failures is how the system learns where its boundaries are. It is also how the human operator can trust the system. Not because it always succeeds, but because it says clearly what happened.
Trust does not come from pretending the system is always right. It comes from preserving the evidence needed to understand when it was right, when it was wrong, and when it did not know enough.
From exploration to reuse
How many times do you see a new open-source tool or research paper and think:
"Interesting — I should test whether this could improve my application."
In static software delivery, that question usually becomes a backlog item. Someone has to read the paper, inspect the repository, understand the interfaces, design an experiment, write glue code, run the test, and decide whether the idea is worth integrating.
In a Living Code System, that loop can become part of the system itself.
A deep research workflow finds a promising paper or open-source tool.
The knowledge layer ingests it into the graph: claims, assumptions, supported modes, contracts, failure modes, expected outputs, and candidate experiments.
Relevant skills are updated so the Agent Code can see the new option in context.
Then the Agent Code can decide whether to test a new feature, reuse existing blocks, create new code when allowed, run the experiment, record evidence, and decide whether the result should be reused, rejected, or hardened into ordinary software.
This does not mean the system rewrites itself randomly.
The principle is the opposite: runtime reasoning should live at the frontier where uncertainty exists. When a path proves stable, it should become a reusable recipe, a tested block, a script, or eventually deterministic application code.
Static code is not the enemy. Static code is where stable knowledge should eventually live.
The missing infrastructure
If Living Code becomes a real delivery pattern, two optimizations become obvious.
The first is specialization.
Today, most agent coders are general-purpose and trained primarily to generate code. Living Code needs a narrower role: inspect context, reuse tools and skills, respect artifact contracts, evaluate strategies, write code only when necessary, preserve evidence, and stop for review.
This may justify a specialized agent coder trained for Living Code Systems — one that keeps the software perimeter low.
The second optimization is subtraction.
OpenClaw contains many useful primitives, but Living Code does not need a universal operating layer for every agentic system. It needs a smaller, sharper profile: skills, contracts, context, tools, telemetry, budget controls, human review, ACP handoff, replay, and evidence preservation.
The opportunity is not to build the Kubernetes of agentic systems.
The opportunity is to define the smallest useful control plane for Living Code Systems.
The new boundary
We are exploring a new software delivery pattern.
Not only static code.
Not unrestricted autonomy.
A Living Code System ships software with Agent Code inside a controlled application boundary.
The application still owns the hard contracts. But some intelligence remains alive at runtime: choosing strategies, using tools, writing software when allowed, recording evidence, and stopping for review.
That is the shift: from delivering static software artifacts to delivering living systems.