Ontology Inference from QA Datasets
Identify which relations a QA dataset actually tests — and which parts of the domain are missing entirely.
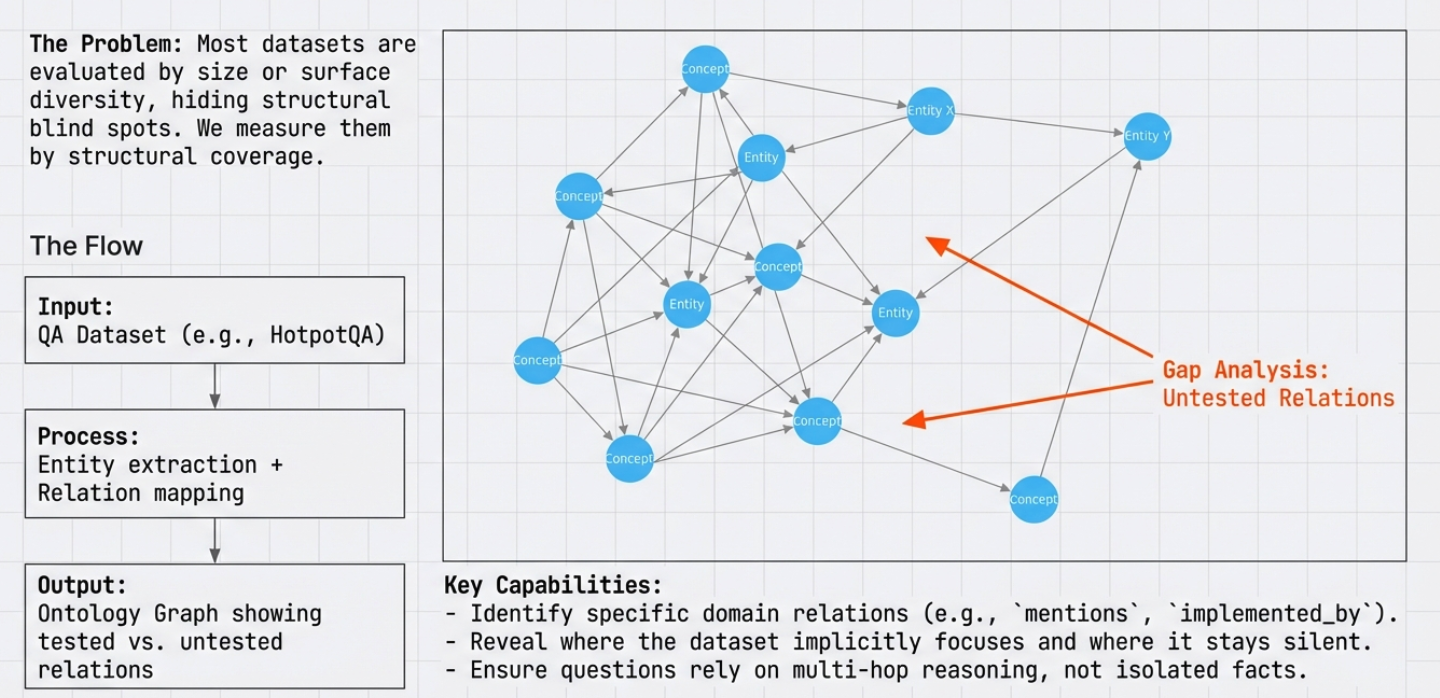
What This Use Case Shows
Most QA datasets are evaluated by size, accuracy, or surface diversity. This use case shows a different perspective: structural coverage.
By aligning questions to an explicit ontology, qa-tools makes it possible to answer:
Which relations are never tested?
Identify blind spots in domain coverage.
Which areas are over- or under-represented?
See structural bias in the data.
Where does the dataset stay silent?
Find implicit focus and missing areas.
Dataset Selection: HotpotQA
Ontology analysis only makes sense when questions rely on relationships, not isolated facts. We use HotpotQA as the reference dataset because:
Step 1 — Build the Ontology from Sources
We start from sources, not questions. qa-tools extracts a domain ontology from Wikipedia passages referenced by HotpotQA supporting facts.
Entity Classes
- Person
- Organization
- Location
- Work
Relations
- born_in(Person → Location)
- member_of(Person → Organization)
- founded(Organization → Organization)
- author_of(Person → Work)
This ontology defines what can be asked, not what happens to be asked.
Step 2 — Map Questions to Relations
Each HotpotQA question is mapped to the relations it relies on.
Question: "Which band was formed first, Nirvana or Pearl Jam?" Mapped relations: • formed_in(Organization → Date) • Organization ↔ Organization (comparison)
For each question, qa-tools records the relations involved and entities referenced as queryable metadata.
Step 3 — Analyze Coverage
With this alignment in place, we compare all relations defined in the ontology against relations actually used by questions.
Relation Covered by QA ─────────────────────────────── born_in Yes member_of Yes founded No subsidiary_of No dissolved_in No
This reveals structural bias not visible from question counts alone:
- Biographical relations (birth, nationality, education) are heavily tested
- Organizational relations (subsidiaries, acquisitions) are largely absent
Acting on the Results
Because gaps are expressed in terms of ontology relations, they are directly actionable. qa-tools can generate questions only for uncovered relations:
Acquisition structures
Ownership and acquisition relationships.
Parent–subsidiary
Corporate hierarchy relationships.
Organizational dynamics
Mergers, dissolutions, restructuring.
This turns ontology analysis into a driver for targeted dataset improvement.
Why This Matters
Ontology-aligned analysis makes dataset limitations explicit and measurable. Instead of guessing whether a dataset is "diverse enough", you can see:
Knowledge emphasized
What the dataset covers well.
Knowledge missing
Gaps and blind spots in coverage.
Coverage evolution
How it changes over time.
Essential for evaluation, benchmarking, and governed dataset extension.